Confidence Graphs: Representing Model Uncertainty in Deep Learning¶
Hendrik Jacob van Veen hendrik.vanveen@nubank.com.br • https://mlwave.com
Matheus Facure matheus.facure@nubank.com.br • https://matheusfacure.github.io/
Last run 2021-10-08 with kmapper version 2.0.1
Introduction¶
Variational inference (MacKay, 2003) gives a computationally tractible measure of uncertainty/confidence/variance for machine learning models, including complex black-box models, like those used in the fields of gradient boosting (Chen et al, 2016) and deep learning (Schmidhuber, 2014).
The \(MAPPER\) algorithm (Singh et al, 2007) [.pdf] from Topological Data Analysis (Carlsson, 2009) turns any data or function output into a graph (or simplicial complex) which is used for data exploration (Lum et al, 2009), error analysis (Carlsson et al, 2018), serving as input for higher-level machine learning algorithms (Hofer et al, 2017), and more.
Dropout (Srivastava et al, 2014) can be viewed as an ensemble of many different sub-networks inside a single neural network, which, much like bootstrap aggregation of decision trees (Breiman, 1996), aims to combat overfit. Viewed as such, dropout is applicable as a Bayesian approximation (Rubin, 1984) in the variational inference framework (Gal, 2016) (.pdf)
Interpretability is useful for detecting bias in and debugging errors of machine learning models. Many methods exist, such as tree paths (Saabas, 2014), saliency maps, permutation feature importance (Altmann et al, 2010), locally-fit white box models (van Veen, 2015) (Ribeiro et al, 2016). More recent efforts aim to combine a variety of methods (Korobov et al, 2016) (Olah et al, 2018).
Motivation¶
Error analysis surfaces different subsets/types of the data where a model makes fundamental errors. When building policies and making financial decisions based on the output of a model it is not only useful to study the errors of a model, but also the confidence:
Correct, but low-confidence, predictions for a cluster of data tells us where to focus our active learning (Dasgupta et al, 2009) - and data collection efforts, so as to make the model more certain.
Incorrect, but high-confidence predictions, surface fundamental error types that can more readily be fixed by a correction layer (Schapire, 1999) [.pdf], or redoing feature engineering (Guyon et al, 2006).
Every profit-maximizing model has a prediction threshold where a decision is made (Hardt et al, 2016). However, given two equal predictions, the more confident predictions are preferred.
Interpretability methods have focussed either on explaining the model in general, or explaining a single sample. To our knowledge, not much focus has gone in a holistic view of modeled data, including explanations for subsets of similar samples (for whatever pragmatic definition of “similar”, like “similar age”, “similar spend”, “similar transaction behavior”). The combination of interpretability and unsupervised exploratory analysis is attractive, because it catches unexpected behavior early on, as opposed to acting on faulty model output, and digging down to find a cause.
Experimental setup¶
We will use the MNIST dataset (LeCun et al, 1999), Keras (Chollet et al, 2015) with TensorFlow (Abadi et al, 2016), NumPy (van der Walt et al., 2011), Pandas (McKinney, 2010), Scikit-Learn (Pedregosa et al, 2011), Matplotlib (Hunter, 2007), and KeplerMapper (Saul et al, 2017).
To classify between the digits 3 and 5, we will train a Multi-Layer Perceptron (Ivakhnenko et al, 1965) with 2 hidden layers, Backprop (LeCun et al, 1998) (pdf), RELU activation (Nair et al, 2010), ADAM optimizer (Kingma et al, 2014), dropout of 0.5, and softmax output, to classify between the digits 3 and 5.
We perform a 1000 forward passes to get the standard deviation and variance ratio of our predictions as per (Gal, 2016, page 51) [.pdf].
Closely following the \(FiFa\) method from (Carlsson et al, 2018, page 4) we then apply \(MAPPER\) with the 2D filter function
[predicted probability(x), confidence(x)]to project the data. We cover this projection with 10 10% overlapping intervals per dimension. We cluster with complete single-linkage agglomerative clustering (n_clusters=3) (Ward, 1963) and use the penultimate layer as the inverse \(X\). To guide exploration, we color the graph nodes bymean absolute error(x).We also ask predictions for the digit 4 which was never seen during training (Larochelle et al, 2008), to see how this influences the confidence of the network, and to compare the graphs outputted by KeplerMapper.
For every graph node we show the original images. Binary classification on MNIST digits is easy enough to resort to a simple interpretability method to show what distinguishes the cluster from the rest of the data: We order each feature by z-score and highlight the top 10% features (Singh, 2016).
[1]:
%matplotlib inline
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import backend as K
from tensorflow.keras.datasets import mnist
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout
from tensorflow.keras.optimizers import Adam
tf.compat.v1.disable_eager_execution()
import kmapper as km
import numpy as np
import pandas as pd
from sklearn import metrics, cluster, preprocessing
import xgboost as xgb
from matplotlib import pyplot as plt
plt.style.use("ggplot")
Preparing Data¶
We create train and test data sets for the digits 3, 4, and 5.
[2]:
# get the data, shuffled and split between train and test sets
(X_train, y_train), (X_test, y_test) = mnist.load_data()
X_strange = X_train[y_train == 4]
y_strange = y_train[y_train == 4]
X_train = X_train[np.logical_or(y_train == 3, y_train == 5)]
y_train = y_train[np.logical_or(y_train == 3, y_train == 5)]
X_test = X_test[np.logical_or(y_test == 3, y_test == 5)]
y_test = y_test[np.logical_or(y_test == 3, y_test == 5)]
X_strange = X_strange[:X_test.shape[0]]
y_strange = y_strange[:X_test.shape[0]]
X_train = X_train.reshape(-1, 784)
X_test = X_test.reshape(-1, 784)
X_strange = X_strange.reshape(-1, 784)
X_train = X_train.astype('float32')
X_test = X_test.astype('float32')
X_strange = X_strange.astype('float32')
X_train /= 255
X_test /= 255
X_strange /= 255
print(X_train.shape[0], 'train samples')
print(X_test.shape[0], 'test samples')
print(X_strange.shape[0], 'strange samples')
# convert class vectors to binary class matrices
y_train = (y_train == 3).astype(int)
y_test = (y_test == 3).astype(int)
y_mean_test = y_test.mean()
print(y_mean_test, 'y test mean')
11552 train samples
1902 test samples
1902 strange samples
0.5310199789695058 y test mean
Model¶
Model is a basic 2-hidden layer MLP with RELU activation, ADAM optimizer, and softmax output. Dropout is applied to every layer but the final.
[3]:
batch_size = 128
num_classes = 1
epochs = 10
model = Sequential()
model.add(Dropout(0.5, input_shape=(784,)))
model.add(Dense(512, activation='relu', input_shape=(784,)))
model.add(Dropout(0.5))
model.add(Dense(512, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(num_classes, activation='sigmoid'))
model.summary()
model.compile(loss='binary_crossentropy',
optimizer=Adam(),
metrics=['accuracy'])
WARNING:tensorflow:From /mnt/c/Users/deargle/projects/kepler-mapper/.venv/lib/python3.6/site-packages/tensorflow/python/ops/resource_variable_ops.py:1666: calling BaseResourceVariable.__init__ (from tensorflow.python.ops.resource_variable_ops) with constraint is deprecated and will be removed in a future version.
Instructions for updating:
If using Keras pass *_constraint arguments to layers.
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dropout (Dropout) (None, 784) 0
_________________________________________________________________
dense (Dense) (None, 512) 401920
_________________________________________________________________
dropout_1 (Dropout) (None, 512) 0
_________________________________________________________________
dense_1 (Dense) (None, 512) 262656
_________________________________________________________________
dropout_2 (Dropout) (None, 512) 0
_________________________________________________________________
dense_2 (Dense) (None, 1) 513
=================================================================
Total params: 665,089
Trainable params: 665,089
Non-trainable params: 0
_________________________________________________________________
Fitting and evaluation¶
[4]:
history = model.fit(X_train, y_train,
batch_size=batch_size,
epochs=epochs,
verbose=1,
validation_data=(X_test, y_test))
score = model.evaluate(X_test, y_test, verbose=0)
score
Train on 11552 samples, validate on 1902 samples
Epoch 1/10
11552/11552 [==============================] - 1s 69us/sample - loss: 0.2475 - accuracy: 0.8908 - val_loss: 0.0753 - val_accuracy: 0.9679
Epoch 2/10
11552/11552 [==============================] - 1s 55us/sample - loss: 0.1360 - accuracy: 0.9481 - val_loss: 0.0541 - val_accuracy: 0.9800
Epoch 3/10
11552/11552 [==============================] - 1s 59us/sample - loss: 0.1152 - accuracy: 0.9546 - val_loss: 0.0456 - val_accuracy: 0.9816
Epoch 4/10
11552/11552 [==============================] - 1s 56us/sample - loss: 0.0943 - accuracy: 0.9625 - val_loss: 0.0349 - val_accuracy: 0.9890
Epoch 5/10
11552/11552 [==============================] - 1s 55us/sample - loss: 0.0821 - accuracy: 0.9699 - val_loss: 0.0337 - val_accuracy: 0.9905
Epoch 6/10
11552/11552 [==============================] - 1s 56us/sample - loss: 0.0765 - accuracy: 0.9709 - val_loss: 0.0291 - val_accuracy: 0.9916
Epoch 7/10
11552/11552 [==============================] - 1s 56us/sample - loss: 0.0704 - accuracy: 0.9721 - val_loss: 0.0306 - val_accuracy: 0.9905
Epoch 8/10
11552/11552 [==============================] - 1s 55us/sample - loss: 0.0650 - accuracy: 0.9752 - val_loss: 0.0268 - val_accuracy: 0.9911
Epoch 9/10
11552/11552 [==============================] - 1s 56us/sample - loss: 0.0602 - accuracy: 0.9782 - val_loss: 0.0272 - val_accuracy: 0.9932
Epoch 10/10
11552/11552 [==============================] - 1s 56us/sample - loss: 0.0538 - accuracy: 0.9800 - val_loss: 0.0249 - val_accuracy: 0.9916
[4]:
[0.024926556563680573, 0.9915878]
Perform 1000 forward passes on test set and calculate Variance Ratio and Standard Dev¶
[5]:
model.layers[-1].output
#K.function([model.layers[0].input, K.learning_phase()], [model.layers[-1].output])
[5]:
<tf.Tensor 'dense_2/Sigmoid:0' shape=(None, 1) dtype=float32>
[6]:
FP = 1000
predict_stochastic = K.function([model.layers[0].input, K.learning_phase()], [model.layers[-1].output])
y_pred_test = np.array([predict_stochastic([X_test, 1]) for _ in range(FP)])
y_pred_stochastic_test = y_pred_test.reshape(-1,y_test.shape[0]).T
y_pred_std_test = np.std(y_pred_stochastic_test, axis=1)
y_pred_mean_test = np.mean(y_pred_stochastic_test, axis=1)
y_pred_mode_test = (np.mean(y_pred_stochastic_test > .5, axis=1) > .5).astype(int).reshape(-1,1)
y_pred_var_ratio_test = 1 - np.mean((y_pred_stochastic_test > .5) == y_pred_mode_test, axis=1)
test_analysis = pd.DataFrame({
"y_true": y_test,
"y_pred": y_pred_mean_test,
"VR": y_pred_var_ratio_test,
"STD": y_pred_std_test
})
print(metrics.accuracy_score(y_true=y_test, y_pred=y_pred_mean_test > .5))
print(test_analysis.describe())
0.9900105152471083
y_true y_pred VR STD
count 1902.000000 1902.000000 1902.000000 1902.000000
mean 0.531020 0.541584 0.022761 0.056355
std 0.499168 0.471860 0.071618 0.079852
min 0.000000 0.000002 0.000000 0.000002
25% 0.000000 0.007583 0.000000 0.004349
50% 1.000000 0.895764 0.000000 0.022617
75% 1.000000 0.998284 0.006000 0.070076
max 1.000000 1.000000 0.498000 0.370983
Plot test set confidence¶
[7]:
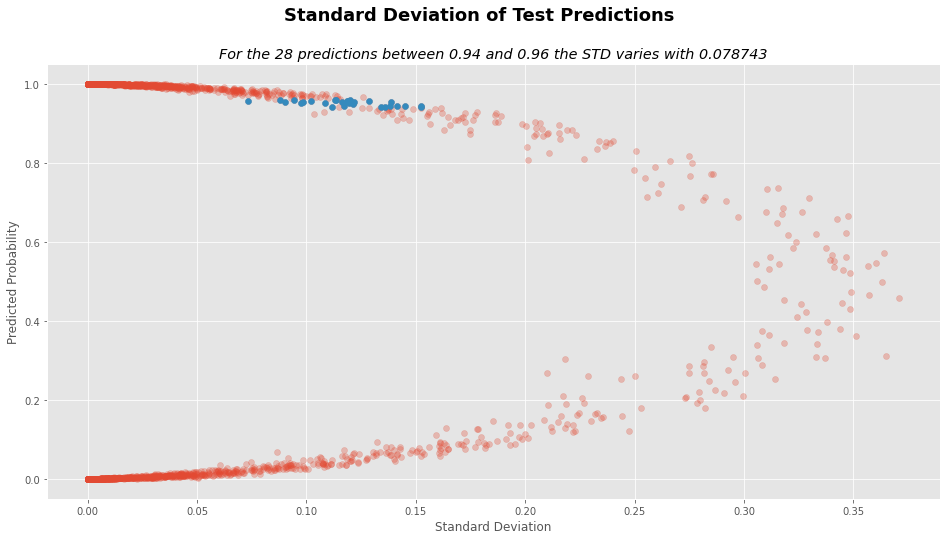
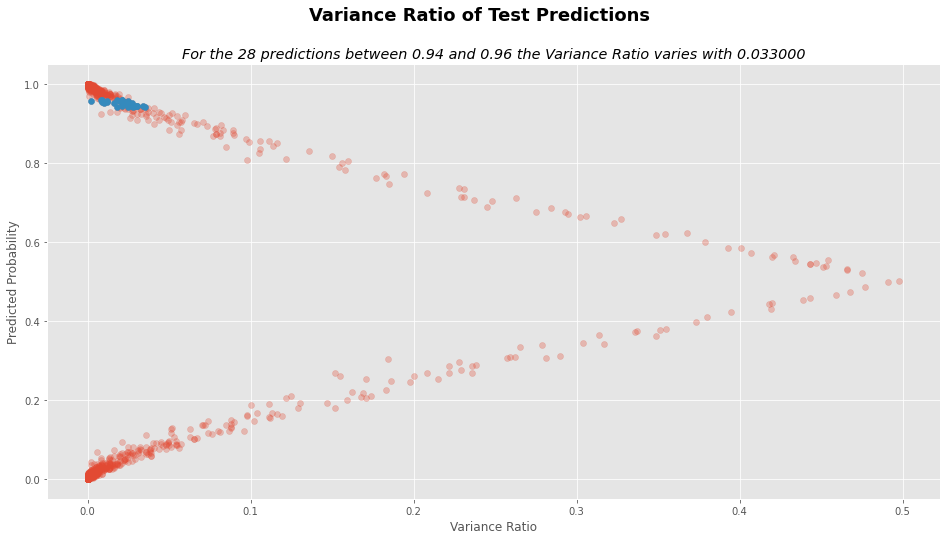
prediction_cut_off = (test_analysis.y_pred < .96) & (test_analysis.y_pred > .94)
std_diff = test_analysis.STD[prediction_cut_off].max() - test_analysis.STD[prediction_cut_off].min()
vr_diff = test_analysis.VR[prediction_cut_off].max() - test_analysis.VR[prediction_cut_off].min()
num_preds = test_analysis.STD[prediction_cut_off].shape[0]
# STD plot
plt.figure(figsize=(16,8))
plt.suptitle("Standard Deviation of Test Predictions", fontsize=18, weight="bold")
plt.title("For the %d predictions between 0.94 and 0.96 the STD varies with %f"%(num_preds, std_diff),
style="italic")
plt.xlabel("Standard Deviation")
plt.ylabel("Predicted Probability")
plt.scatter(test_analysis.STD, test_analysis.y_pred, alpha=.3)
plt.scatter(test_analysis.STD[prediction_cut_off],
test_analysis.y_pred[prediction_cut_off])
plt.show()
# VR plot
plt.figure(figsize=(16,8))
plt.suptitle("Variance Ratio of Test Predictions", fontsize=18, weight="bold")
plt.title("For the %d predictions between 0.94 and 0.96 the Variance Ratio varies with %f"%(num_preds, vr_diff),
style="italic")
plt.xlabel("Variance Ratio")
plt.ylabel("Predicted Probability")
plt.scatter(test_analysis.VR, test_analysis.y_pred, alpha=.3)
plt.scatter(test_analysis.VR[prediction_cut_off],
test_analysis.y_pred[prediction_cut_off])
plt.show()
Apply \(MAPPER\)¶
Take penultimate layer activations from test set for the inverse \(X\)¶
[8]:
predict_penultimate_layer = K.function([model.layers[0].input, K.learning_phase()], [model.layers[-2].output])
X_inverse_test = np.array(predict_penultimate_layer([X_test, 1]))[0]
print((X_inverse_test.shape, "X_inverse_test shape"))
((1902, 512), 'X_inverse_test shape')
Take STD and error as the projected \(X\)¶
[9]:
X_projected_test = np.c_[test_analysis.STD, test_analysis.y_true - test_analysis.y_pred]
print((X_projected_test.shape, "X_projected_test shape"))
((1902, 2), 'X_projected_test shape')
Create the confidence graph \(G\)¶
[10]:
mapper = km.KeplerMapper(verbose=2)
G = mapper.map(X_projected_test,
X_inverse_test,
cover = km.Cover(n_cubes=10,
perc_overlap=0.5),
clusterer=cluster.AgglomerativeClustering(n_clusters=2)
)
KeplerMapper(verbose=2)
Mapping on data shaped (1902, 512) using lens shaped (1902, 2)
Minimal points in hypercube before clustering: 2
Creating 100 hypercubes.
> Found 2 clusters in hypercube 0.
> Found 2 clusters in hypercube 1.
> Found 2 clusters in hypercube 2.
> Found 2 clusters in hypercube 3.
Cube_4 is empty.
Cube_5 is empty.
> Found 2 clusters in hypercube 6.
> Found 2 clusters in hypercube 7.
Cube_8 is empty.
> Found 2 clusters in hypercube 9.
> Found 2 clusters in hypercube 10.
> Found 2 clusters in hypercube 11.
> Found 2 clusters in hypercube 12.
> Found 2 clusters in hypercube 13.
> Found 2 clusters in hypercube 14.
> Found 2 clusters in hypercube 15.
> Found 2 clusters in hypercube 16.
> Found 2 clusters in hypercube 17.
> Found 2 clusters in hypercube 18.
> Found 2 clusters in hypercube 19.
> Found 2 clusters in hypercube 20.
> Found 2 clusters in hypercube 21.
> Found 2 clusters in hypercube 22.
> Found 2 clusters in hypercube 23.
> Found 2 clusters in hypercube 24.
> Found 2 clusters in hypercube 25.
> Found 2 clusters in hypercube 26.
> Found 2 clusters in hypercube 27.
Cube_28 is empty.
> Found 2 clusters in hypercube 29.
> Found 2 clusters in hypercube 30.
> Found 2 clusters in hypercube 31.
> Found 2 clusters in hypercube 32.
> Found 2 clusters in hypercube 33.
> Found 2 clusters in hypercube 34.
> Found 2 clusters in hypercube 35.
> Found 2 clusters in hypercube 36.
> Found 2 clusters in hypercube 37.
Cube_38 is empty.
> Found 2 clusters in hypercube 39.
> Found 2 clusters in hypercube 40.
> Found 2 clusters in hypercube 41.
> Found 2 clusters in hypercube 42.
> Found 2 clusters in hypercube 43.
> Found 2 clusters in hypercube 44.
> Found 2 clusters in hypercube 45.
> Found 2 clusters in hypercube 46.
> Found 2 clusters in hypercube 47.
> Found 2 clusters in hypercube 48.
> Found 2 clusters in hypercube 49.
> Found 2 clusters in hypercube 50.
> Found 2 clusters in hypercube 51.
> Found 2 clusters in hypercube 52.
> Found 2 clusters in hypercube 53.
> Found 2 clusters in hypercube 54.
Created 272 edges and 100 nodes in 0:00:01.160742.
Create color function output (absolute error)¶
[11]:
color_function_output = np.sqrt((y_test-test_analysis.y_pred)**2)
Create image tooltips for samples that are interpretable for humans¶
[12]:
import io
import base64
from skimage.util import img_as_ubyte
from PIL import Image
# Create z-scores
hard_predictions = (test_analysis.y_pred > 0.5).astype(int)
o = np.std(X_test, axis=0)
u = np.mean(X_test[hard_predictions == 0], axis=0)
v = np.mean(X_test[hard_predictions == 1], axis=0)
z_scores = (u-v)/o
# scores with lowest z-scores (error) first
scores_0 = sorted([(score,i) for i, score in enumerate(z_scores) if str(score) != "nan"],
reverse=False)
# scores with highest z-scores (error) first
scores_1 = sorted([(score,i) for i, score in enumerate(z_scores) if str(score) != "nan"],
reverse=True)
# Fill RGBA image array with top 200 scores for positive and negative
img_array_0 = np.zeros((28,28,4))
img_array_1 = np.zeros((28,28,4))
## Color the 200 regions with lowest error yellow, with decreasing transparency
for e, (score, i) in enumerate(scores_0[:200]):
y = i % 28
x = int((i - (i % 28))/28)
img_array_0[x][y] = [255,255,0,205-e]
## Color the 200 regions with highest error red, with decreasing transparency
for e, (score, i) in enumerate(scores_1[:200]):
y = i % 28
x = int((i - (i % 28))/28)
img_array_1[x][y] = [255,0,0,205-e]
img_array = (img_array_0 + img_array_1)
# lighten intensity of colors a bit for RGB channels
img_array[:,:,:3] = img_array[:,:,:3] / 2
# Get base64 encoded version of this. Will be displayed under each tooltip image.
output = io.BytesIO()
img_array = img_as_ubyte(img_array.astype('uint8'))
img = Image.fromarray(img_array, 'RGBA').resize((64,64))
img.save(output, format="PNG")
contents = output.getvalue()
explanation_img_encoded = base64.b64encode(contents)
output.close()
from IPython import display
display.Image(base64.b64decode(explanation_img_encoded))
/mnt/c/Users/deargle/projects/kepler-mapper/.venv/lib/python3.6/site-packages/ipykernel_launcher.py:14: RuntimeWarning: invalid value encountered in true_divide
[12]:

[13]:
# The testing data -- it is a 28x28 matrix of 0 / 1 (black/white) pixel data.
# Example below for test data 0.
Image.fromarray(img_as_ubyte(X_test[0].reshape((28,28))), 'L').resize((64,64))
[13]:

[14]:
# Create tooltips for each digit.
# Overlay the "explanation image" on top of each test data point.
tooltip_s = []
for ys, image_data in zip(y_test, X_test):
output = io.BytesIO()
_image_data = img_as_ubyte(image_data.reshape((28,28))) # Data was a flat row of "pixels".
img = Image.fromarray(_image_data, 'L').resize((64,64))
img.save(output, format="PNG")
contents = output.getvalue()
img_encoded = base64.b64encode(contents)
img_tag = """<div style="width:71px;
height:71px;
overflow:hidden;
float:left;
position: relative;">
<img src="data:image/png;base64,%s" style="position:absolute; top:0; right:0" />
<img src="data:image/png;base64,%s" style="position:absolute; top:0; right:0;
opacity:.75; width: 64px; height: 64px;" />
<div style="position: relative; top: 0; left: 1px; font-size:9px">%s</div>
</div>"""%((img_encoded.decode('utf-8'),
explanation_img_encoded.decode('utf-8'),
ys))
tooltip_s.append(img_tag)
output.close()
tooltip_s = np.array(tooltip_s)
Visualize¶
[15]:
_ = mapper.visualize(G,
lens=X_projected_test,
lens_names=["Uncertainty", "Error"],
custom_tooltips=tooltip_s,
color_values=color_function_output.values,
color_function_name=['Absolute error'],
title="Confidence Graph for a MLP trained on MNIST",
path_html="output/confidence_graph_output.html")
Wrote visualization to: output/confidence_graph_output.html
[16]:
# Uncomment and run the below to view the visualization within the juptyer notebook
#
# from kmapper import jupyter
# jupyter.display("output/confidence_graph_output.html")
Image of former output¶

Link to former output¶
Changelog¶
2021.10.8 – Dave Eargle (@deargle)¶
add
tf.compat.v1.disable_eager_execution()to make runnable by tensorflow 2.xadd
color_function_nameto make compatible with kmapper v2.xchange perc_overlap from 0.8 to 0.5 to make match the output at http://mlwave.github.io/tda/confidence-graphs.html (note that both differ from the descriptive text at the top of the document – unsure why)
replace deprecated
scipy.miscimage functions withpillow.Imagefor loading from an array and for resizing, and img_as_ubyte for bytescalingincrease explanation image alpha channel and overlay opacity to make match output at at http://mlwave.github.io/tda/confidence-graphs.html
Note that the introductory descriptive text suggests that AgglomerativeClustering n_clusters will be 3, but the code sets it to 2. I suspect that the descriptive text is wrong and the code is right.